...
| Section | ||||||
|---|---|---|---|---|---|---|
| ||||||
|
| Excerpt |
|---|
FeaturesHere, yo willl find some of the new release's features. Check out the Change Log for further information on all changes. Contentanalyzer Service ControllableThe Contentanalyzer service provides a simple text extraction and the determination of the MIME type as a synchronous "service" for the analysis of objects. Statically - and therefore comprehensively - you can set the service for each object using the JSON configuration file so that text extraction ( For a dynamic control of the text extraction of the service—for example, in connection with compound documents where this is not required—the Tracing Options (New Endpoints)Two new system endpoints tell you more about the state of DMS calls (
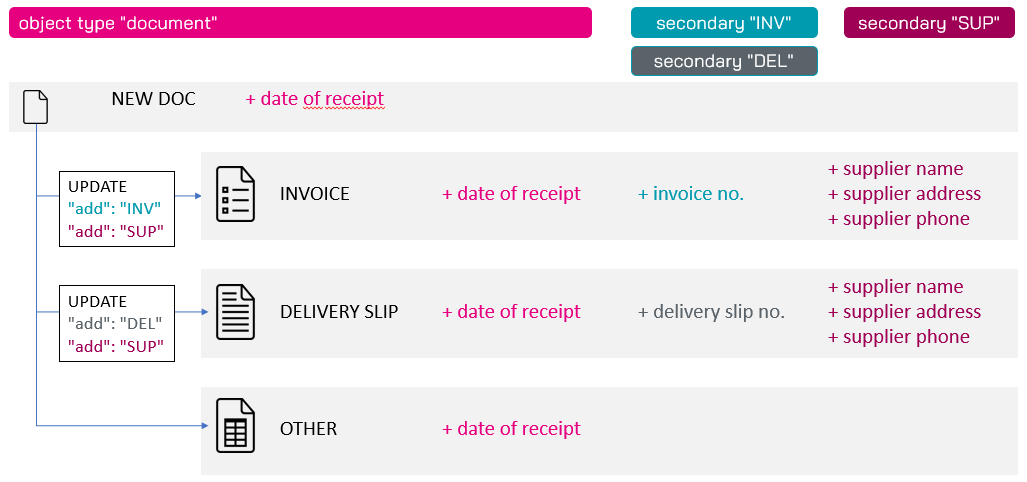
The result, which is provided in JSON format, contains per call information about Document Lifecycle Management"Schema Flow" Using Floating Secondary Object TypesFlexible structural change of the schema ... For the greatest possible flexibility in all lifecycles of an object, we provide floating secondary object types ("dynamic") in addition to static ones. The already existing concept of "static" secondary object types, which can be used to group properties and then assign these property groups to object types (e.g., documents or folders), has been enhanced. So called "floating" secondary object types allow you to make schema changes for individual object type instances during the lifecycle and thus flexibly adapt them to your management processes. For example, you can classify imported objects only at a later point in time and add or remove the necessary property groups of a floating secondary object type at runtime by updating its type.
For an object type, you define references to secondary object types in the schema definition: e.g.,
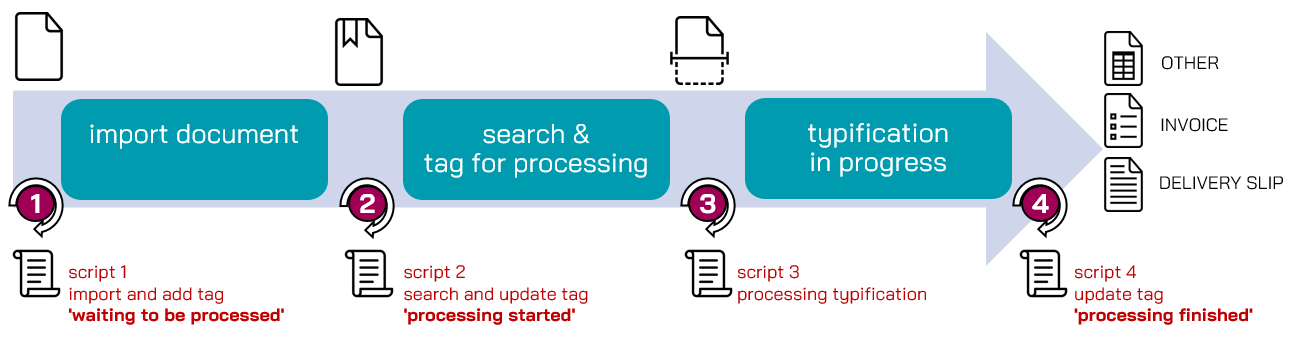
Note that values for the secondary object type's properties must be given if set to Search for objects that use secondary object types by explicitly specifying it in the FROM clause: >> "Secondary Object Types" concept | "Changing Schema Structures ("Schema Flow")" tutorial. Traceable, Stateful Processing of Documents Using TagsIn document lifecycle management, multi-stage and asynchronous processes are not uncommon—quite the contrary. The first process steps are carried out with the highest priority. More complex and currently not absolutely essential process steps are carried out asynchronously with a lower priority. This saves time, and carrying out operations in parallel lets you distribute resources more evenly. To resume a process chain, additional information about the current status of the process is necessary. In order to not mix an object's metadata with its status data, we introduced the possibility to tag objects. Tags describe the status of an object within a process chain. They consist of a unique tag name ( Objects can be searched by tags and selected for the next process step. All tagging activities are recorded by the yuuvis® system in the object history (Audit Trail). Thanks to this, you can always retrace who has done what and when. Trouble shooting, reporting on the process status or general issues are made easy by this centrally stored history. Five new endpoints are available for the handling of tags:
Typical use cases are combinations of third-party applications, whose process chains are controlled by a certain tag (i.e., workflows or renditions). You can learn about the different options in our tutorial, where we take you through a simple import management process for subsequent classification of imported documents (code samples are included).
>> "Tagging Objects for Processing" tutorial plus code examples in gitHub |
| Section | ||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|