Platform Overview
- Technische Redaktion
A set of APIs and tools that enables customers to set up and use AI functionalities by themselves.
Table of Contents
Platform Concept
The Artificial Intelligence Platform is a set of APIs and tools that enable customers to set up and use AI functionalities by themselves, yet with low costs and high performance.
Customers can export their own documents, train models using different algorithms provided by OPTIMAL SYSTEMS GmbH, evaluate trained models, and deploy to make predictions.
Every part of the AI Platform can be deployed on-premises or in the cloud.
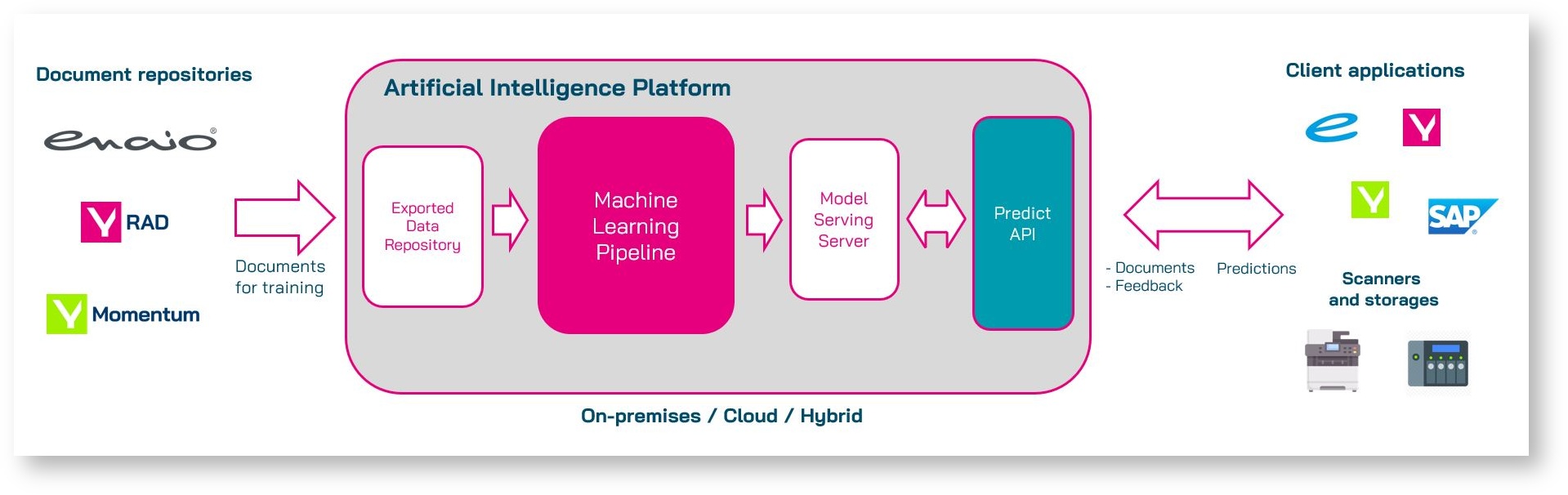
Platform Components
Model Training
The Model Training part of the platform is responsible for storing exported data from yuuvis® Momentum (documents, metadata), preprocessing exported data, machine learning training, model evaluation, etc.
There are two main components:
- Exported data repository – a physical place where exported data are stored.
- ML Training Pipeline – the component responsible for the preprocessing of data, AI model training, and model evaluation.
Model Serving
The Model Serving part of the platform is responsible for serving predictions to the calling application (yuuvis® Momentum client application, 3rd party applications, scanners, etc.).
There are two main components:
- Model Serving – infrastructure that runs dockerized AI models that perform classification or metadata-extraction from documents. Can be deployed on-premises or in the cloud.
- PREDICT-API Service – responsible for calling appropriate machine learning models, aggregating, improving, and validating results, and finally rendering responses to the calling application.
Platform Managing
KAIROS platform is configured using KAIROS-API service to manage the Inference Schema. This allows system integrators to configure use of classifiers and metadata extractors for the whole system or for each of the tenants.
Infrastructure
Serving and platform management components are dockerized and can be deployed to any infrastructure that supports Docker/Kubernetes, on-premises, or in the cloud.
The Model Training is installed directly into a host operating system. This will be changed in future versions, and training will be dockerized and fully Kubernetes compatible as well.
To support the customers that have sensitive data and do not want their documents to leave their on-premises systems, the the model training can be executed in their own infrastructure and once the models are dockerized, they can be used on-premises or in the cloud, according to customers' needs.
Flow Description
Since this is an end-to-end platform, the flow will be best described using the most common use case: metadata extraction from invoices.
The whole process can be done in just 8 steps.
- Export documents and their metadata in a predefined format (e.g., 5,000 invoices received from different partners/suppliers).
- Check exported documents and their metadata (remove those without metadata or with wrong metadata).
- Decide which metadata shall be extracted and train the corresponding ML Training Pipelines.
- Evaluate the model performance.
- Repeat steps 1 to 5 or 3 to 5 until you are satisfied with the results.
- Dockerize and deploy the models.
- Define Inference Schema (set usage of the model for the appropriate document type).
- Use PREDICT-API Service to extract the metadata from new invoices in your client application.